
KG Construction From Unstructured Text
Published:
Lots of valuable information is available on the web such as Twitter, legal documents, financial/sports news and scientific articles as unstructured data. Although a lot of Knowledge Graphs (KGs) including WikiData and DBPedia are made publicly available, it may be necessary to create our own KG for an analysis that we would like to perform. By converting text to KG, we can obtain new knowledge and new insights from text sources. In this blog, we will discuss what Natural Language Processing (NLP) methods and tools should be used to build KGs.
There are many application areas where you can use the KG built from text like Content Search, Recommendation and Classification.
Content search
Content recommendation
Content classification
We can use the KG generated from the content to classify and annotate with keywords (concepts) and can be searchable with the keywords and variations of these keywords. Many modern applications (like Netflix and YouTube) rely on recommendation systems to create optimal customer experiences. A lot of these systems rely on named entity recognition, which can make suggestions based on user search history. For example, if you watch a lot of comedies on Netflix, you’ll get more recommendations that have been classified as the entity Comedy.
Another use for a KG is to develop smarter applications by augmenting the original text source. We can integrate data from a book and the KG constructed from it, making the content more easily discoverable. As a matter of fact, DBPedia has created a KG using Wikipedia articles. Many applications have been using both DBPedia and Wikipedia at the same time.
Converting unstructured data into a KG is a common task when there are no existing KGs to perform an analysis on. However, it is important to have a good understanding of the steps this conversion requires and the challenges related to conversion to a KG.
Let's take a simple sentence.
Albert Einstein was a German-born theoretical physicist who developed the theory of relativity.
We aim to build a KG that follows a certain semantic structure and convert the sentence to the KG in the figure.
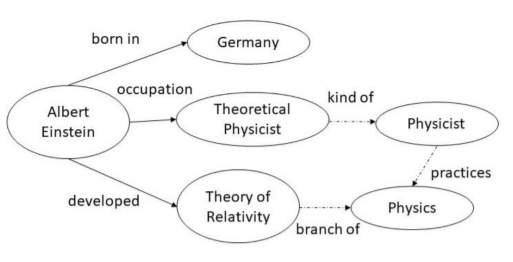
When we skim the entities in the given sentence, we can identify entities such as "Albert Einstein", "German", "Theoretical physicist" and "theory of relativity". However, We need to include some entities (‘Physics’) or relations (‘occupation’, ‘branch’) that do not appear in the sentence into our KG to make it semantically consistent. If we want to follow a certain semantic schema (ontology), for example, "theory of relativity" should probably be a sub-branch of “physics.” This entity also can be connected to a Physicist who practises “physics.”
The information extraction tasks needed to construct a KG from a text data can be classified into three subtasks. To begin with, we need to determine the entities that appear in text. NER is trained to detect entities and their types, such as 'people' or 'companies'.’The second step is to link or map the extracted entities to knowledge base/graph objects. For example, “apple” can be mapped as the fruit in the database, or also as a company.This task is called NEL or Entity resolution. The final step is the relation extraction which is applied to determine the relationships between the extracted entities.
The entities mentioned in this paragraph are identified in two ways: by determining the location of the noun/noun phrases in the sentence and assigning them a type from a selected vocabulary. For example, the entity “Albert Einstein” found in the text is annotated with the 'PERSON' type, while”German(y)” is labelled with the 'Location' type.
[PER Albert Einstein]was a [LOC German]-born theoretical physicist who is best known for developing the theory of relativity. In[TIME 1905], he was awarded a PhD by the [ORG University of Zurich]and received the [TIME 1921] Nobel Prize in Physics "for his services to theoretical physics.
Also, the task of NER can be seen as a simple machine learning problem, in which each word/word phrase among the specific types can be assigned to a type. Besides being the most basic step of creating a KG, NER can help Search and Recommendation systems make the content more findable by annotating these entities.
Named Entity recognition approaches include Dictionary-based or rule based where you create a dictionary of all entities and/or rules to identify entities and Machine learning methods in which HMM and CRF are commonly used models.
The current successful methods are mostly NN-based methods. Among them, Attention and Transfer learning mechanisms are the most used methods.
Named Entity Linking (NEL) task aims to map extract entities to objects in a target ontology or knowledge base. Apart from creating a KG, they have the following other applications. For example, if we find the word “Floyd” in a sentence, we may not be sure if it means Pink Floyd or “Floyd” (a person’s name) or “Floyd_Iowa” (a city).
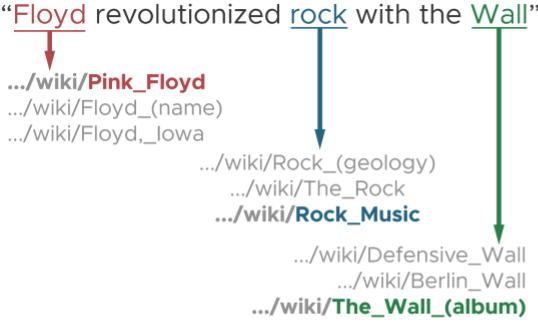
There are some of the important challenges that arise while applying NER and NEL in a domain. NER/NEL is a complex task due to problems of name variation and ambiguity. Name variation is the use of different names for an entitys. For example, the entity “Michael Jeffrey Jordan” can be referred to using numerous names, such as Michael Jordan, MJ, and Jordan. The ambiguity problem refers to the fact that a name may refer to different entities depending on the context. If you cannot find a suitable model for the domain you have chosen, you have to create your own model, which usually requires training data.
Albert Einstein born in Germany
Albert Einstein occupation Theoretical physicist
Theoretical physicist branch of Physics
……
Relation extraction is the task of identifying relationships between two or more entities, so it is about extracting relationships between entities subsequent to recognizing entities. In fact, it can be used to find new knowledge between two entities or to test the correctness of a relationship. In addition, the KG resulting from this information can be used to automatically generate a Question Answering answer to the wrong question.
Next post we will be talking about how to create a domain-specific knowledge graph using NLP tools. The tools that we use are the Spacy and Hugging Face BERT model.
SpaCy: a Python framework known for being fast and very easy to use. It has an excellent statistical system that you can use to build customized NER extractors.